First, let me begin by setting some expectations. This is not a guide for the hardcore ML researchers out there. This is meant to be a practical introduction to machine learning that any computer scientist can follow, without much prior knowledge of the ML domain. I feel that there are many guides that focus solely on the academics of ML, but neglect to mention how simple it is to apply towards real life applications. Even naive approaches are often surprisingly effective.
To get started, we need to install scikit and other dependencies.
For simple implementations like we’ll see today, most of the challenge revolves around data prep. Our first step is to download the JSON training data from Kaggle. If you don’t already have an account, you’ll need to create one now. Once the account is created, visit the “What’s Cooking?” competition page and select the data tab to access the downloads.
Next, we need to format the data. A CSV format will be used, with each column representing a different ingredient and each row a single recipe. In ML lingo, the ingredients are features, the data we use as a basis for the predictions. Labels, the answer to each recipe, will be generated similarly. There’s nothing too novel with the code here, just some data wrangling.
Create a file called parser.py with the following code:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 | #!/usr/bin/env python3 # Enable python2 compatability from __future__ import print_function import json def main(): # Define input/output file names train_file = "train.json" test_file = "test.json" train_file_out = "train.csv" test_file_out = "test.csv" train_file_out_labels = "train-labels.txt" json_data = None with open(train_file, ‘r’) as f: json_data = f.read() train_obj = json.loads(json_data) # Empty arrays to hold information labels_train = [] labels_test = [] # ingredients is defined as a set to prevent duplicates ingredients = set() # Generate corresponding labels and simultaneously make # exhaustive set of all posible cuisines (labels) with open(train_file_out_labels, ‘w’) as f: for recipe in train_obj: label = recipe["cuisine"] print(label, file=f) labels_train.append(label) for ingredient in recipe["ingredients"]: ingredients.add(ingredient) with open(test_file, ‘r’) as f: json_data = f.read() test_obj = json.loads(json_data) # The test file may introduce ingredients not included in training set # This ensures they’re included for recipe in test_obj: for ingredient in recipe["ingredients"]: ingredients.add(ingredient) # Transform set to list to ensure iteration order is constant ingredients_list = list(ingredients) # Generate the CSV files generate_csv_for_each_recipe(ingredients_list, train_obj, train_file_out) generate_csv_for_each_recipe(ingredients_list, test_obj, test_file_out) def generate_csv_for_each_recipe(ingredients_list, json_obj, output_file): """ Creates an output csv file with each ingredient being a column and each recipe a row. 1 will represent the recipe contains the given ingredient if the recipe includes that incredient, else 0 ingredients_list — the full list of ingredients (without duplicates) json_obj — the json object with recipes returned by json.loads output_file — the name of the generated CSV file """ # Loop thru each recipe with open(output_file, ‘w’) as f: for recipe in json_obj: rl = set() first = True s = "" for ingredient in recipe["ingredients"]: rl.add(ingredient) # This builds the csv row of ingredients for current recipe # Add 1 for ingredient if included in recipe; else 0 for j in ingredients_list: # Don’t prepend "," for first item if first != True: s += "," else: first = False # Add 1 or 0 as explained above if j not in rl: s += "0" else: s += "1" print(s, file=f) if __name__ == "__main__": main() |
Create a new python script called train.py. Add some simple imports and variables that will prove useful later.
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
filename = "train.csv"
label_file = "train-labels.txt"
test_file = "test.csv"
prediction_output = "predictions.txt"
Load the data files generated previously with the parser script.
features = np.loadtxt(filename, delimiter=‘,’, dtype=np.uint8)
# Load the labels
with open(label_file) as f:
labels = f.readlines()
# Strip any new line characters or extra spaces
labels = [x.strip() for x in labels]
# Convert to np array
labels = np.asarray(labels)
The next step is to split the training data into a training set and a testing set. This will allow us to estimate how well the classifier does on the “real” test data. Think about it, the testing data from Kaggle does not include the answers (labels). To have an easy way to see how well we’re doing, it’s necessary to split the data we do have answers for. It is not okay to test with the same features used in training — the accuracy will be artificially high. Scikit includes a handy feature to split the data for us.
X_train, X_test, y_train, y_test = train_test_split(features, labels)
Instantiate and train the classifier with the split data set created from the last step. Selecting the best classifier is beyond the scope of this article, so we’ll just use the Logistic Regression classifier in this example, which performs pretty well. Scikit has an example testing different classifiers, if you want to explore.
clf = LogisticRegression()
clf.fit(X_train, y_train)
score = clf.score(X_test, y_test)
print("Model has accuracy of " + str(score * 100) + "%")
Let’s use the same classifier to make predictions over the Kaggle test set, the one we don’t know the answers to. We’ll format this as simply one prediction per line.
test_data = np.loadtxt(test_file, delimiter=‘,’, dtype=np.uint8)
predictions = clf.predict(test_data)
with open(prediction_output, "w") as f:
for prediction in predictions:
print(prediction, file=f)
The last script we’ll write takes the predictions created in the last step and formats it in the specific way Kaggle expects. This will let us see how we performed against other solutions to the What’s Cooking Challenge.
Create a new script called kaggle.py. As usual, import the required modules and define a few helpful variables.
from __future__ import print_function
import json
predict_file = "predictions.txt"
test_file = "test.json"
output_file = "kaggle.csv"
Read the prediction file
labels = f.readlines()
labels = [x.strip() for x in labels]
Open the Kaggle test file and parse as JSON
json_data = f.read()
obj = json.loads(json_data)
Open the output file for writing and format as the Kaggle spec requires.
# Print CSV headers
print("id,cuisine", file=out)
i = 0
# Iterate through each recipe in the test file
# Follow the spec in CSV format,
# the recipe id followed by the cuisine prediction
for recipe in obj:
idx = recipe["id"]
ingredient = labels[i]
print(str(idx) + "," + ingredient, file=out)
i += 1
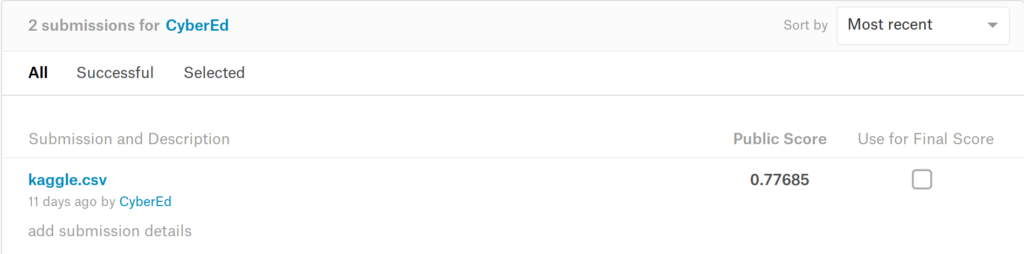
To see how well you did, submit the generated kaggle.csv file to the Kaggle competition.
The complete code is available on GitHub.
For such a naive solution, we did pretty well here — successfully classifying over 77% of the recipes. There is, of course, room for improvement. It’s unlikely you’ll top the leader board with ready-made classifiers, but it’s close enough for many real-life problems and an excellent start to a future in machine learning.



Leave a Reply